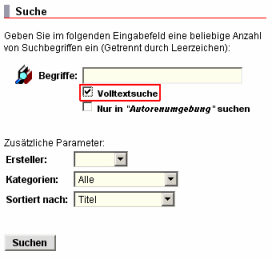
Volltextsuche
Zusätzlich zu der vom WebGenesis®-Basissystem bereitgestellten Suche in Feldern ist mit Hilfe Dienstes IREngine eine Freitextsuche in Inhalten und alternativer Darstellung auf Basis eines booleschen Information Retrieval Systems (IR-System) möglich.
Die technischen Anforderungen an ein solches System sind in /IREngine/ beschrieben.
Wenn der Dienst Volltextsuche installiert ist, erscheint bei der Maske gezielte Suche zusätzlich das Markierungsfeld Volltextsuche.
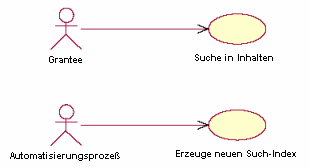
Vorgehensweise und Funktionalität
- Erzeuge neuen Such-Index
- Suche in Inhalten
Neuen Such-Index erzeugen
Um eine performante Suche zu ermöglichen, legt die IR-Engine mit Hilfe des automatisch im Hintergrund ablaufenden Indexierungsprozesses regelmäßig Hilfsinformationen, den sog. Index ab. Suchanfragen führen nicht zu einer direkten Suche in den Dokumenten; vielmehr wird der Index durchsucht.
Der Index besteht aus zwei Komponenten:
- Der Directory-Index ist eine Repräsentation der gesamten Dokumentenliste, die hierarchisch innerhalb des Dateisystems realisiert ist. Der Directory-Index enthält Verweise auf die eigentlichen Dokumentdateien und merkt sich das Datum der letzten Änderung aller Dateien.
- Der Term-Index enthält die Liste aller in den Dokumenten vorkommenden Terme (Stichwörter), die charakteristisch für ein Dokument sind. Für jeden Term wird auch die Liste der Verweise, in welchen Dokumenten der Term vorkommt, geführt. Um eine schnelle Suche nach Termen zu gewährleisten, ist der TermIndex als AV L-Baum organisiert, darunter versteht man einen binären Such-Baum, bei dem alle Äste die gleiche Höhe aufweisen. Um eine Teilwortsuche (Links- und Rechts-Trunkierung) zu ermöglichen, werden auch die Suffixe jedes Terms in den Baum einsortiert.
Da der Index beträchtlich groß werden kann, wird er nicht im Hauptspeicher gehalten, sondern auf einem Sekundärspeicher.
Der Indexierungsprozeß führt in einem festgelegten Intervall eine automatische Reorganisation des gesamten Index durch. Er prüft, welche Dokumente seit der letzten Erzeugung des Index gelöscht, hinzugefügt oder verändert wurden und trägt diese Veränderungen in den Index ein. Die Standardeinstellung für ein Intervall beträgt 1 Stunde. Sie kann durch Konfigurierung geändert werden.
Die Indexierung bezieht zur Zeit folgende Inhaltsformate mit ein:
.txt |
(reine Texte im ANSI oder DOS-Zeichensatz) |
.html |
(wie .txt, jedoch mit Markierungen (tags) zur Browser-Steuerung) |
.doc |
(Microsoft Word-Dokumente) |
.ppt |
(Microsoft Powerpoint-Dokumente) |
.xls |
(Microsoft Excel-Dokumente) |
.pdf |
(Adobe PDF-Dokumente) |
Der Indexierungsprozeß basiert auf Regeln, was indizierbarer Text ist und was nicht. Bei allen Dokumenten werden
- Spezialzeichen (z.B.Satzzeichen, Leerzeichen) ignoriert,
- getrennte Wörter zusammengeführt,
- Wörter, die in der Stoppwortliste vorkommen, gefiltert,
- Wörter, die nur aus Ziffern bestehen oder aus weniger als 3 Zeichen bestehen, gefiltert.
Bei HTML-Dateien werden
- nur der Nutztext außerhalb von Tags indiziert,
- HTML-spezifische Spezialzeichen (z.B. Umlaute) durch entsprechende Unicode Zeichen ersetzt,
- script- und style-Elemente gefiltert.
Die Indexierung von Dateien im PDF-Format erfordert derzeit noch die Einbindung eines externen Hilfsprogrammes. Dieses hat gewisse Einschränkungen, vor allem bei der Behandlung der Trennung, des Blocksatzes und der Sonderzeichen.
Suche in Inhalten
Der Suchausdruck wird in der von WebGenesis® bekannten Form (siehe gezielte Suche) eingegeben. Es wird auf folgende Weise in den Inhalten gesucht:
- Exact match: die kleinste Verletzung der Bedingung führt zum Ausschluß des Dokumentes.
- Substring match: ein Treffer wird angezeigt, wenn der Suchbegriff an beliebiger Stelle innerhalb eines Wortes in einer der Inhaltsdateien gefunden wird.
- Case insensitive: Groß-/Kleinschreibung der Suchbegriffe wird nicht unterschieden.
- Eine UND-Verknüpfung wird durchgeführt, wenn der Ausdruck aus mehreren Begriffen besteht. ODER-Verknüpfungen müssen mit Hilfe mehrerer Anfragen realisiert werden.
Es bestehen (derzeit) folgende Einschränkungen:
- Eine Verfeinerung vorangegangener Abfragen ist derzeit noch nicht möglich. Es muss eine neue Abfrage getätigt w erden.
- Kontextoperatoren, z.B. Wortabstand, könen nicht angegeben werden.
- Eine Gewichtung einzelner Suchterme kann nicht angegeben werden.
- Begriffe aus mehreren Worten werden als UND-Verknüpfung
interpretiert.
Beispiel: &exp;junge Wilde&exp; → &exp;junge behaarte Wilde&exp; würde ebenfalls gefunden.
Als Ergebnis der Suche können in den Templates dargestellt werden:
- Eine Liste der Einträge, bei denen die Suchbegriffe in den Metadaten (Datenbanksuche) und/oder den zugehörigen Inhalten und Layoutdateien (Volltextsuche) gefunden wurden. Die von der Volltextsuche gefundenen Einträge werden gemäß der eingestellten Sortierreihenfolge in die Trefferliste einsortiert und eventuell nach der gewählten Kategorie und dem Benutzer entsprechend gefiltert.
- Eine Liste aller, bei diesen Einträgen von der Volltextsuche
gefundenen, Layout-/Inhaltsdateien, welche den Suchbegriff enthalten.
Für jede Datei wird angezeigt
- der Dateiname (Verweis),
- ggf. ein Verweis auf die zugehörige Textversion,
- die Größe,
- die Anzahl der Treffer,
- ein Textauszug von 200 Zeichen mit mindestes einem markierten Treffer.
Ein Beispiel für ein Suchergebnis:
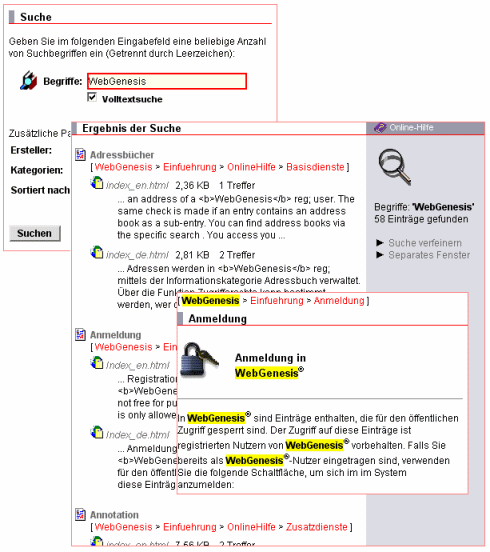
Beim Anklicken eines gefundenen Eintrages oder eines Dateinamens, wird dieser angezeigt. Die Suchbegriffe werden dabei markiert (gelber Hintergrund bei der Grundversion). Muß eine Datei zur Darstellung erst heruntergeladen werden (lokaler Viewer), kann die Markierung der Suchbegriffe nicht wie gewohnt angezeigt werden. Stattdessen wird ein zusätzlicher Verweis auf eine von der IREngine erzeugte Textversion angeboten. Bei der Anzeige der Textversion erscheinen die Treffer markiert.
Die Textversion wird grundsätzlich nur für Inhalts-Dateien, nicht jedoch für Layout-Dateien generiert. Layout-Dateien sind in der Regel HTML-Dateien und erfordern zur Anzeige kein Herunterladen.
Es findet kein Ranking der gefundenen Antworten statt, d.h. die Dokumente werden nicht nach fallender Übereinstimmung sortiert.
Konfiguration
Der System Administrator hat die Möglichkeit folgende Konfigurationen vorzunehmen:
| Indexierungs- intervall |
Zeitabstand (in Sekunden), in dem der Indexierungsprozess
angestoßen wird (Standardwert 1 Stunde). Durch die Angabe von 0
kann der Indexierungsprozess abgeschaltet werden. Die Erzeugung eines neuen Index kann erzwungen werden, indem der Server heruntergefahren, der alte Index gelöscht und danach der Server wieder hochgefahren wird. Beim Hochfahren, stellt das System fest, dass kein Index vorhanden ist und generiert unmittelbar einen neuen. Stellt das System beim Hochfahren fest, dass ein Index vorhanden ist, wird das Indexierungsintervall abgewartet und danach die Aktualisierung (update) des Index angestoßen. Während der Aktualisierungsphase bleibt der "alte" Index aktiv. Die Umschaltung erfolgt, wenn der Aktualisierungslauf vollständig abgeschlossen ist. |
| Reader | Die IREngine stellt mehrere Reader bereit, das sind
Einleseprozeduren für bestimmte Dokumenttypen (siehe
Dokumenttypen). Die Reader werden automatisch
konfiguriert. Jedoch besteht die Möglichkeit einem Reader noch
weitere Dateiendungen zuzuweisen. Die Standardkonfiguration sieht
folgendermaßen aus:
|
| Stoppwort- liste |
Soll eine Stoppwortliste verwendet werden, muss sie in das Verzeichnis des Indexierungsprozesses unter dem Namen stoplist.txt kopiert werden. Eine Standard-Stoppwortliste wird mit ausgeliefert. |
| Ausschluss- liste |
Soll eine Ausschlussliste verwendet werden, muss sie in das Verzeichnis des Indexierungsprozesses unter dem Namen excludelist.txt kopiert werden. Alle Dateien, die sich in einem der hier eingetragenen Verzeichnisse (absolute Pfade oder relativ zum Index-Ordner) befinden, werden von der Indexerzeugung ausgeschlossen. |